
Problem Definition
One of Vendelux’s aims is to not just give our customers intelligence about the events they want to go to, but we want to also tell them about events that they should be going to. Or in more technical terms, we want to do event recommendation.
Customer-centric vs Event-centric Approaches
Recommendation is not a new problem, and there are many ways one can approach this. To start, we can either take a customer-centric approach or an event-centric approach to doing this.
A customer-centric approach can look as such: we group all of our customers based on industry, and even subindustries depending on how granular we want to get. Then we can simply recommend events to a given customer based on the events that their competitors are interested in. A downside of this approach is that if there is only a single customer in a niche, then we can’t recommend much.
One way to address this is to eschew the model of grouping companies by industry, and simply define similarity by the ratio of shared events. Then we can recommend events based on the companies with the highest ratio of shared events, because in theory, these should be the most similar companies. But this doesn’t actually solve the problem because, again, a company that is very niche will likely have very little in terms of shared events with other companies.
If we had a list of all the events that each company in the world is going to, then this is not a problem. This might be a little difficult. So instead, we flip the problem and take an event-centric view to do this. We can define a similarity metric on events. This allows us then to make the assumption: if a given customer is interested in an event, they will probably be interested in similar events because they will probably have similar prospects.
Fair enough, but how do we define a similarity metric on events? We need to somehow turn the event into a vector (hint), then have the distance between those vectors be a measure of the similarity. As you can guess by now, we are going to embed the event.
Implementation
The first step to embedding is feature picking. In a world of seemingly limitless data, compute unfortunately isn’t unlimited (unless you have an unlimited budget, too). So we had to hone in on the dimensions that we felt carried the most signal about the events.
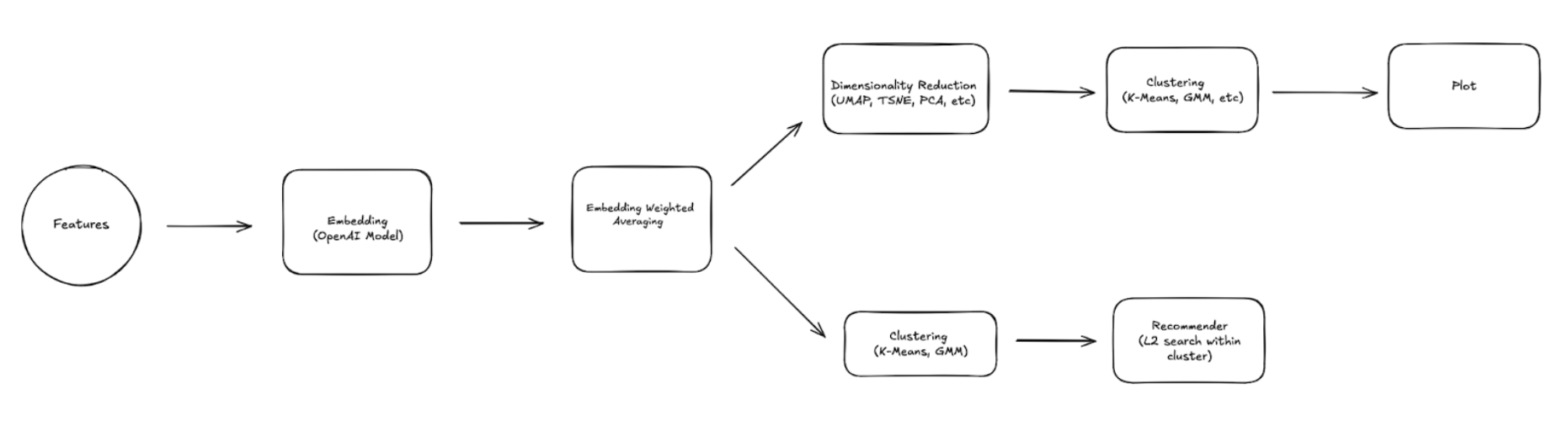
Being a Snowflake shop, we used Snowpark to pull the data, clean it, and filter it as necessary. We then took an unconventional approach: we embedded each feature separately. We could have combined all of the features into a single text field and subsequently gotten the embeddings. However, by doing so we are implicitly giving all the features equal weight. And if one event in our index is missing a field or two, this would impact the efficacy of the results. By embedding each feature separately, we can weigh each feature differently, and we can even learn the weighings that maximize separation between different events, and minimize the distance between similar events.
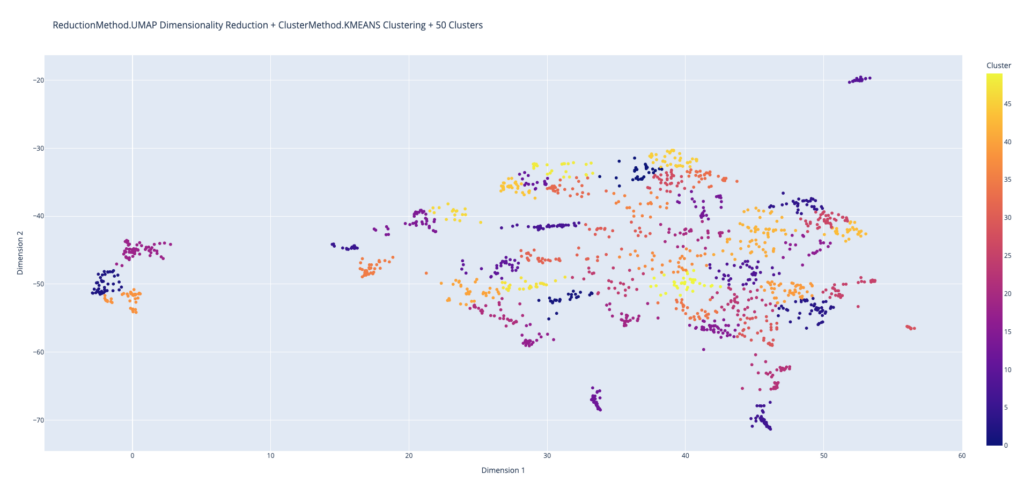
Now is the home stretch. For visualization purposes, we reduced the dimensionality of the weighted average embedding for each event with UMAP, then we clustered with K-means. You can see the result in the graphic below.

Astute readers may ask the question, “that’s a nice plot but where is the recommendation system”. This is not too difficult either. Since we have the embeddings now, a simple L2 search over the event embedding space for the closest K vectors to a given input gives us what we need. And when there is a lot of data, we cluster first. This way, we only have to do a linear search over a given cluster rather than the entire dataset.
The diagram below shows what the final systems looks like:
Conclusion
This was definitely a very fun project to think about during the span of our week-long hackathon. There are many, many, many optimizations that can be done to make this system more robust, more performant, connect it to the customer facing product to make recommendations, etc. but as a first step, this definitely demonstrates the viability of doing recommendations via embeddings and distance metrics.
Thank you so much for taking the time to read this! Feel free to leave a comment below. We would love to hear your thoughts and any questions you may have 🙂
